Artificial Intelligence for Records Management

Automation is the best way to address the major challenges of records management today. But what is automation, really? (See previous article, the Top 3 Challenges of Records Management )
There are two main categories of automation to consider:
Fingerprinting technology: Sample documents are provided to an application that represent the types of content in an organisation. These are analysed by the application to find common characteristics, which could include things like phrasing or formatting. These common characteristics are referred to as the document’s “fingerprints”.
Linguistic analysis: When provided with sample documents the application extracts data and metadata from the samples. It then uses linguistic analytics to determine what records series should be applied to what content.
Within these two main categories there are seven types of automation we typically deal with in the Records Management world. They can use Fingerprinting, Linguistic analysis, or both as methods of automation. All of them help us to classify content correctly against the file plan, and in some cases, we can build relationships between content for event better classification. This also helps us to enhance search and retrieval of information. Collectively, these automation techniques are referred to as Artificial Intelligence (AI).
At RecordPoint we are making significant investments in Research and Development to enhance our products with greater AI capabilities. We have focused on the concepts below and how they apply to Records Management, Information Management, and Information and Data Governance. This article explains the key approaches we are focusing on.
Types of Automation
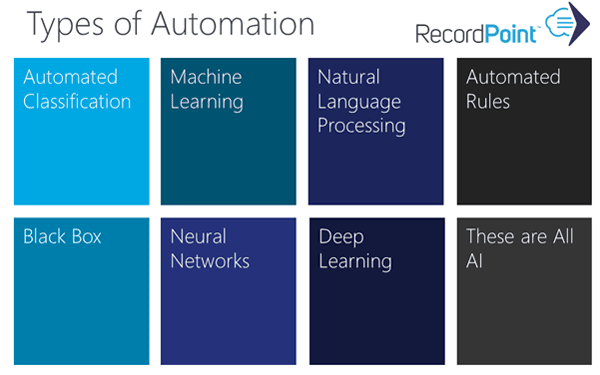
1. Automated Classification
Automated classification is the application of categories, labels, tags, or metadata to content. This can be done using fingerprinting and/or linguistic analysis.
We can understand a lot about content by looking at fingerprints, such as who uploaded it, where they put it, and the document title. From this, we can often infer a classification.
Additionally, we can also look at the content inside the document using linguistic analysis techniques to classify it appropriately.
2. Machine Learning
Machine Learning uses statistical techniques to give computers the ability to learn. In plain English, this means if you are editing a document with a colleague, the computer can infer that you have a stronger relationship with that person than someone who has never authored a document with you.
Once you track these relationships across multiple platforms and content, the computer can know a lot about your work preferences and behaviour, creating a fingerprint that can be used in future cases.
This fingerprint can help us build relationships between documents for records management purposes and help reduce the number of classification errors by recognising what content should be classified as a record.
It can also help us to group together like information, such as all content related to a certain customer across all content sources, which improves productivity and the collaboration experience, in additional to helping us to be more compliant.
3. Natural Language Processing
Natural Language Processing (NLP) is artificial intelligence concerned with the interactions between computers and human (natural) languages. It also looks at how to program computers to process enormous amounts of natural language data using linguistic analysis.
NLP includes a large group of automation tasks, but a few directly apply to records management. First, NLP can be used to identify terms and metadata that are actually relevant to the document, as if a person had manually read and chose terms, rather than the terms that appear most frequency.
Second, optical character recognition (OCR) can recognise text in images and classify them appropriately.
Third, given a chunk of text, NLP can identify the relationships among named entities. For example, it could pull the name of a person from the document and automatically look up what department they work in, even if the department is not mentioned in the document directly.
There are many more examples, but these are just a few.
4. Automated Rules
Automated rules can perform repetitive actions on your behalf. They are triggered when certain criteria are met. For example, when a document is classified as a contract over $500,000, a retention schedule can be automatically applied.
Using fingerprinting and/or linguistic analysis we can automatically identify when the triggers occur and what rules should be used.
5. Black Box
Black box automation is related to NLP and classification. It is another type of automation the identifies relationships between data and predicts the next data in a sequence.
For example, we can count how many times a word appears in a document (top ranked words) or find relevant terms using linguistic analysis. We then would compare it to other similar documents to develop a fingerprint. When a future document matches that fingerprint, we can start to infer what metadata might apply to that document.
This is applied to records management to be able to identify the relationships between content and data, to ensure they are classified correctly and the appropriate retention policy has been applied.
6. Neural Networks
Neural networks improve performance on classification by looking at other examples where a category has been applied, like in fingerprinting.
For example, in image recognition, they might learn to identify images that contain a dog by analysing example images that have been manually labelled as “dog” or “no dog” and using the results to identify dogs in other images.
Neural networks are another tool that helps us better classify content for records management purposes, so we are more confident in the classification and that the correct retention policy has been applied.
7. Deep Learning
Deep learning is a type of machine learning. In this case, deep learning can use a hierarchy of concepts, such as a hierarchical file plan, to classify content.
For example, say your file plan hierarchy is Legal -> Contracts. In deep learning the document would first be identified as a legal document using fingerprinting and/or linguistic analysis, then it would only look at categories under legal to identify it is a contract. This can be repeated over hundreds of layers. In each case the previous layers inform the next layer of classification.
Learn More about Artificial Intelligence Automation
There are certainly a lot of Artificial Intelligence (AI) automation concepts that can apply to records management. It can be daunting to understand them all and how you can get the benefit for your organisation.
The great news is that at RecordPoint, we’re doing the hard work for you, so you can automatically benefit from these technologies by using our products. Our goal is to make it easier for you to automatically identify records and classify content using AI.
Schedule a demo with us and see how we can help your organization benefit from records management automation. Have more questions? No worries. Simply contact us and let us know how we can help you.
Anthony Woodward is Chief Technology Officer & Founder of RecordPoint